AWSコストチェインの頻出パターンを抑え一気にコストを削減する
AWSのコスト削減のために単一のサービスとにらめっこしていても効果が薄いでしょう。複数のサービスが連鎖するコスト構造を理解することで、チェインの起点から修正しレバレッジを効かせて削減することができます。
この記事では、起点側の修正で終点側の呼び出しを抑えるパターンを取り上げます。
*終点側を高速化することで起点も高速化するパターンは除きます。
前提として、大まかなコスト内訳は確認済みとします。
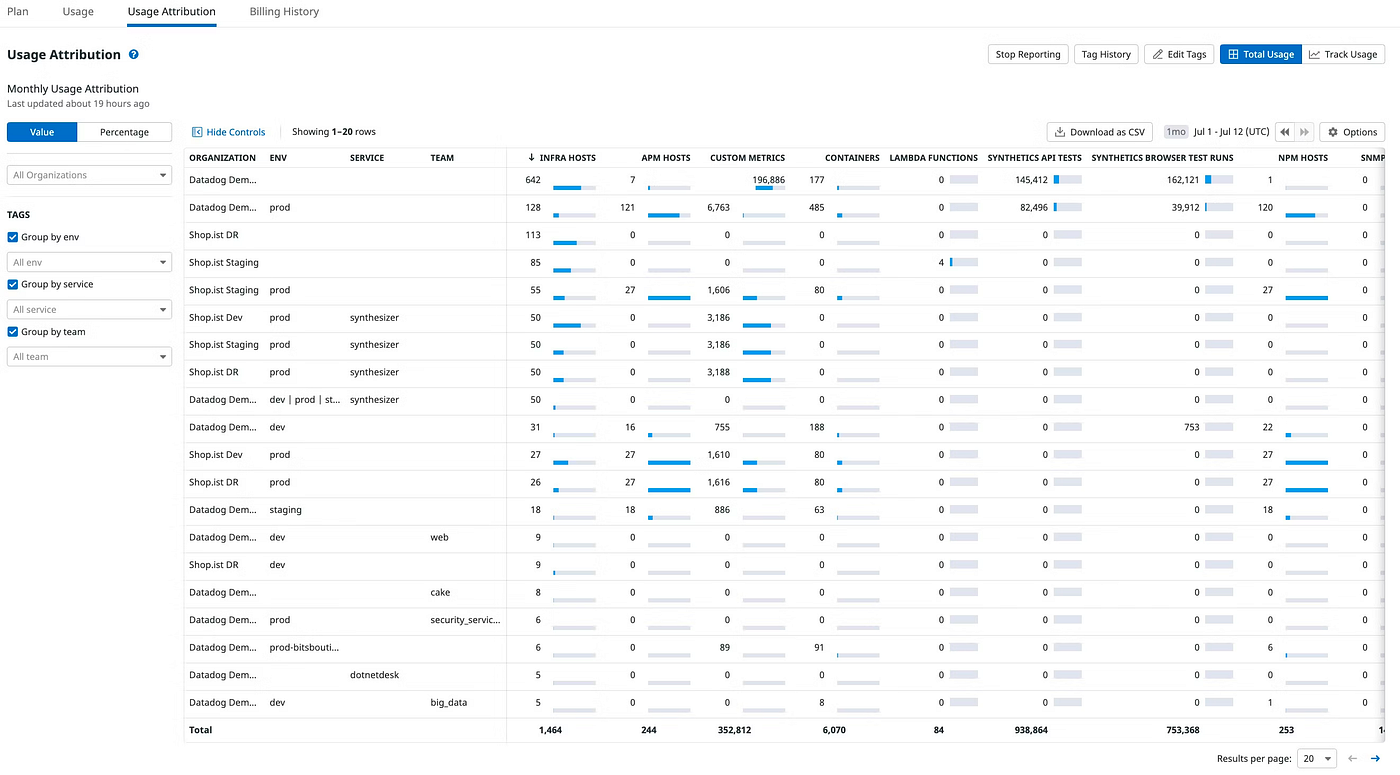
S3 -> CloudTrail -> GuardDuty
S3オブジェクトへのリクエストはCloudTrailにデータイベントという形で記録され、それをGuardDutyが監査する、といったパターンの連鎖です。
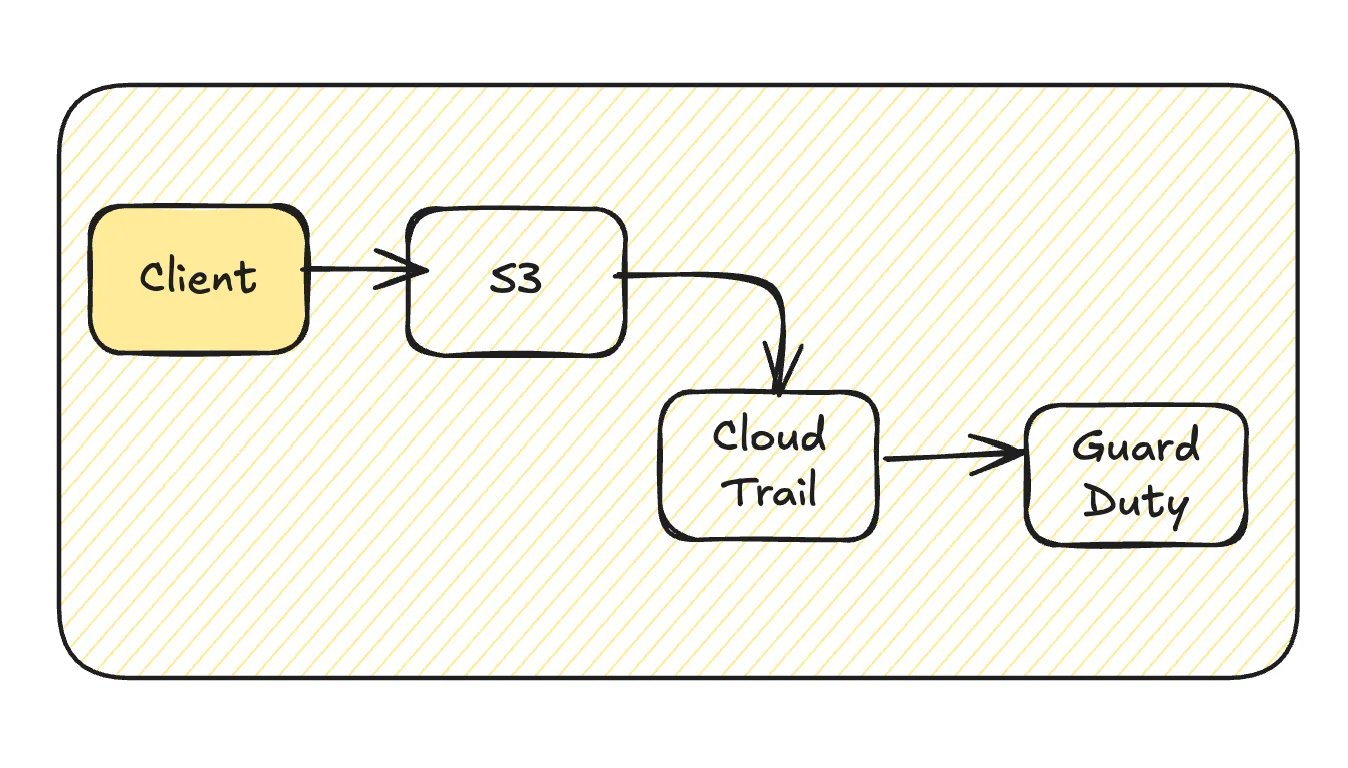
クライアントから抑える
- 外部からのアクセスが嵩むならCloudFrontを挟む (CloudFrontはCloudTrailに記録されない。アクセスログはS3同様取得可能)
- 特にAPIからのS3呼び出しを控え、署名付きURLを活用する
- オブジェクト一覧が必要ならS3 Inventoryを検討する
- データ基盤宛の場合はテーブル形式からジョブのアクセス方式まで見直す
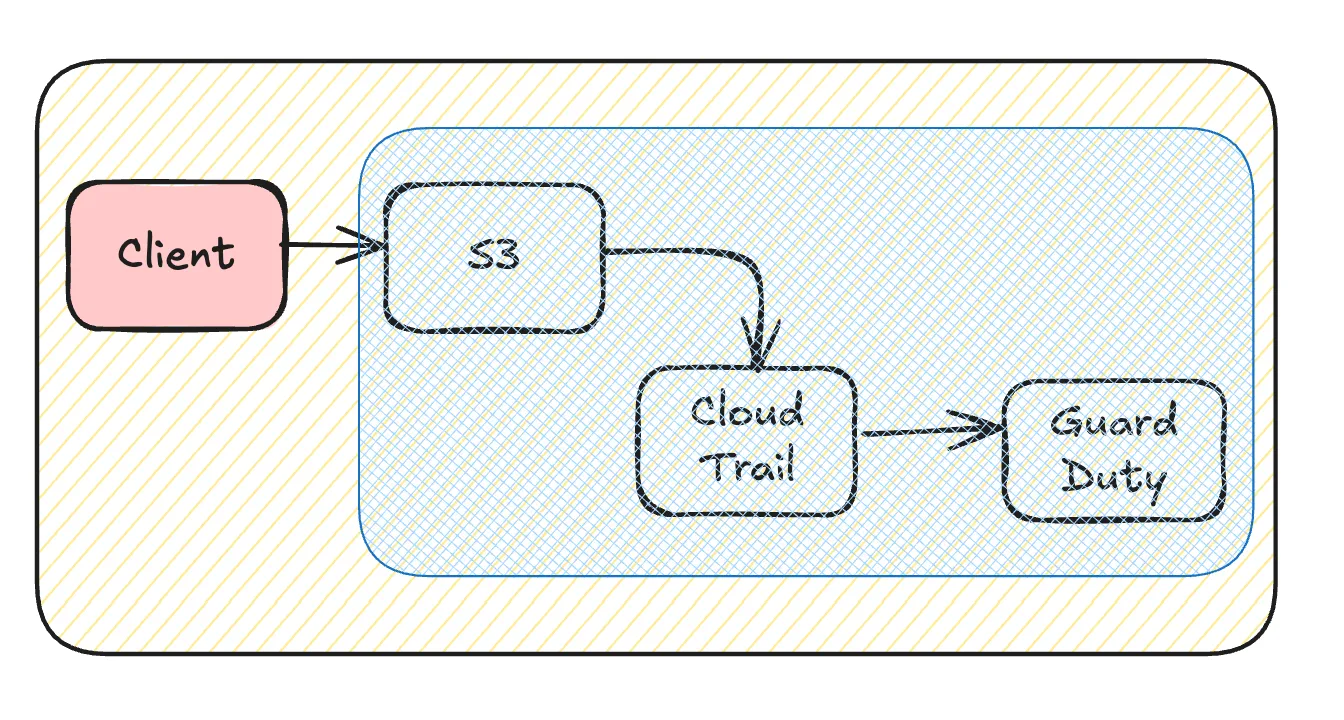
CloudTrailへの記録を抑える
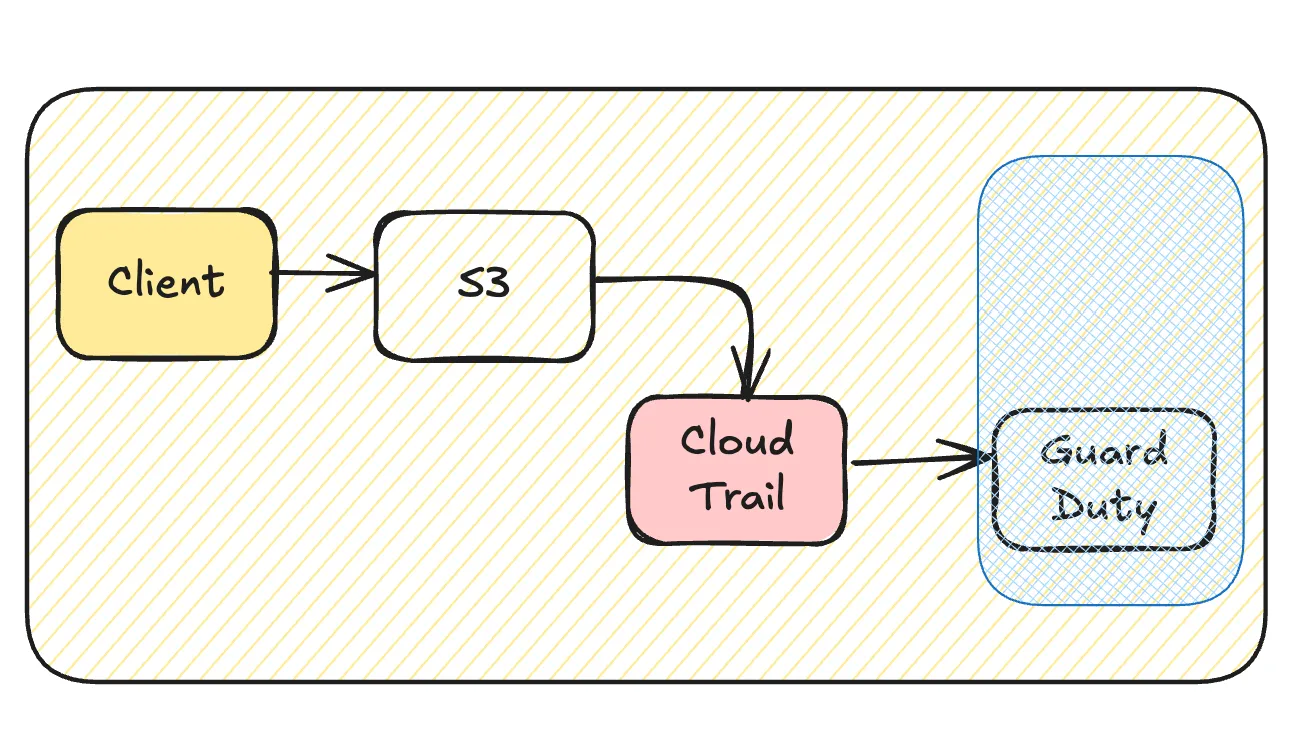
CloudTrailで記録するデータイベントはフィルタリング可能です。AWSアカウントのワークロードと既存のセキュリティ施策、セキュリティ要件に応じて検討しましょう。除くことでこの経路でトレースができなくなりますが支障ないかどうかです。
AWS Config -> SecurityHub -> GuardDuty
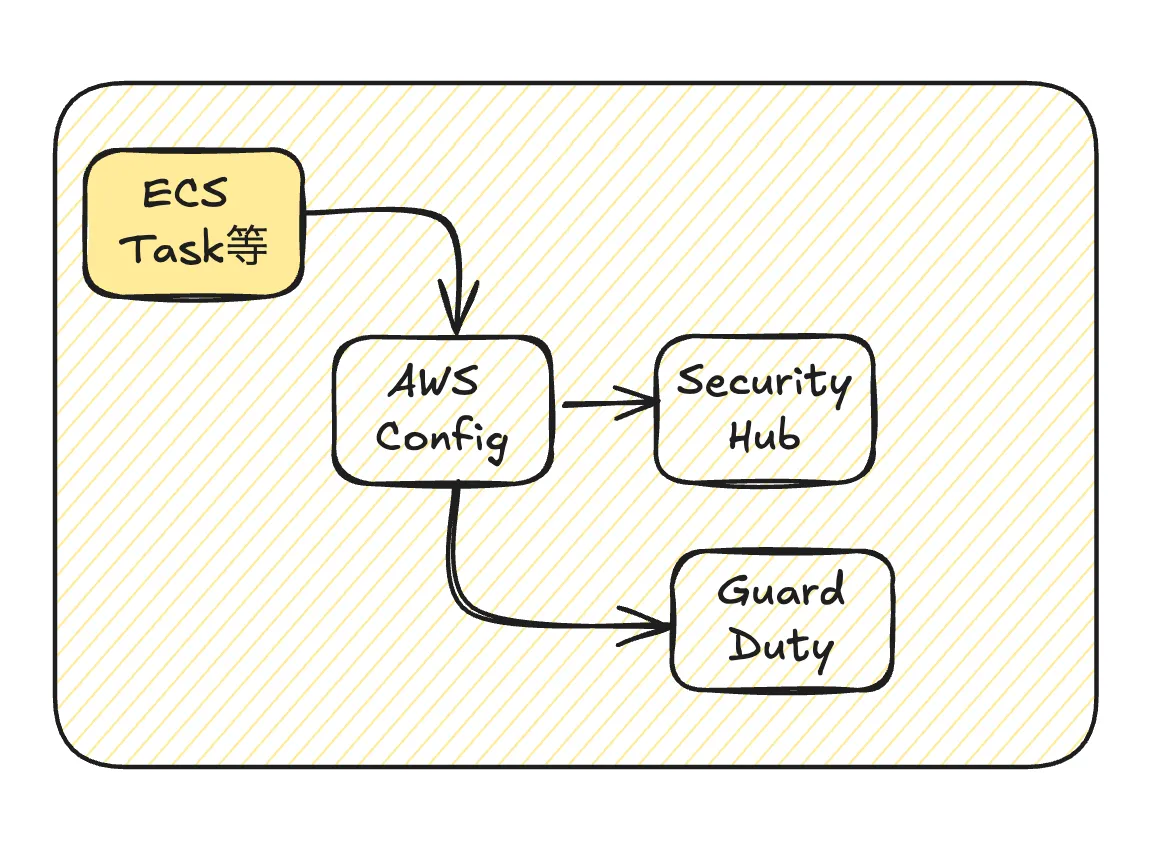
ECS TasksやEC2が起動終了を繰り返すことでネットワークインターフェースなどにアクセスし、それがAWS Configに記録され、さらにSecurity Hubなどで検査される連鎖パターンです
Amazon Inspector起因のパターンもありました
初期トリガーから抑える
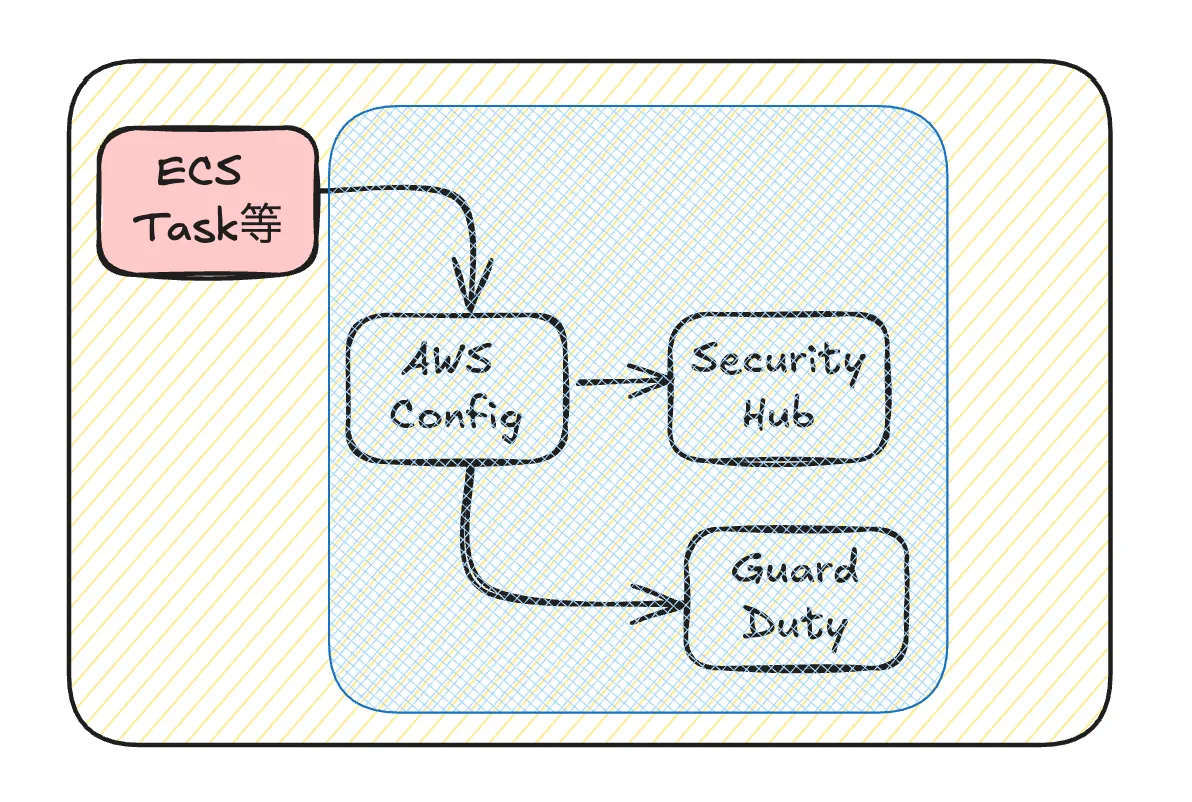
もしECS Taskの数や起動頻度を下げることができれば抑えることができます。率直に言って難しく、アーキテクチャレベルの検討が必要になることが多いでしょう。
AWS Configの記録量を抑える
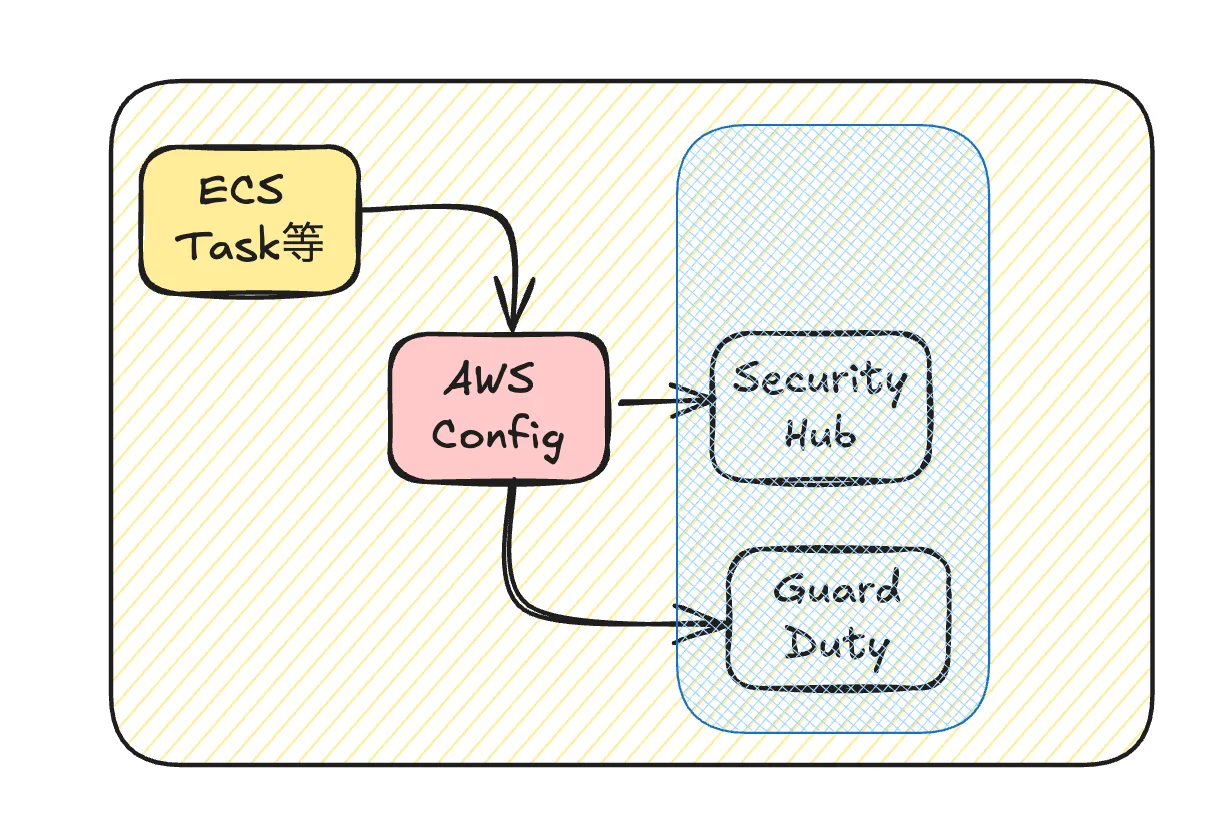
この連鎖ではこちらが本命です。やり方は二種類あります
- 特定の記録種類を除外する
- 随時記録から日次記録に変更する 全体変更のほか特定の記録種類だけに留めることも可能
ワークロードと既存のセキュリティ施策、セキュリティ要件を考慮して選択しましょう。
API Gateway + Lambda
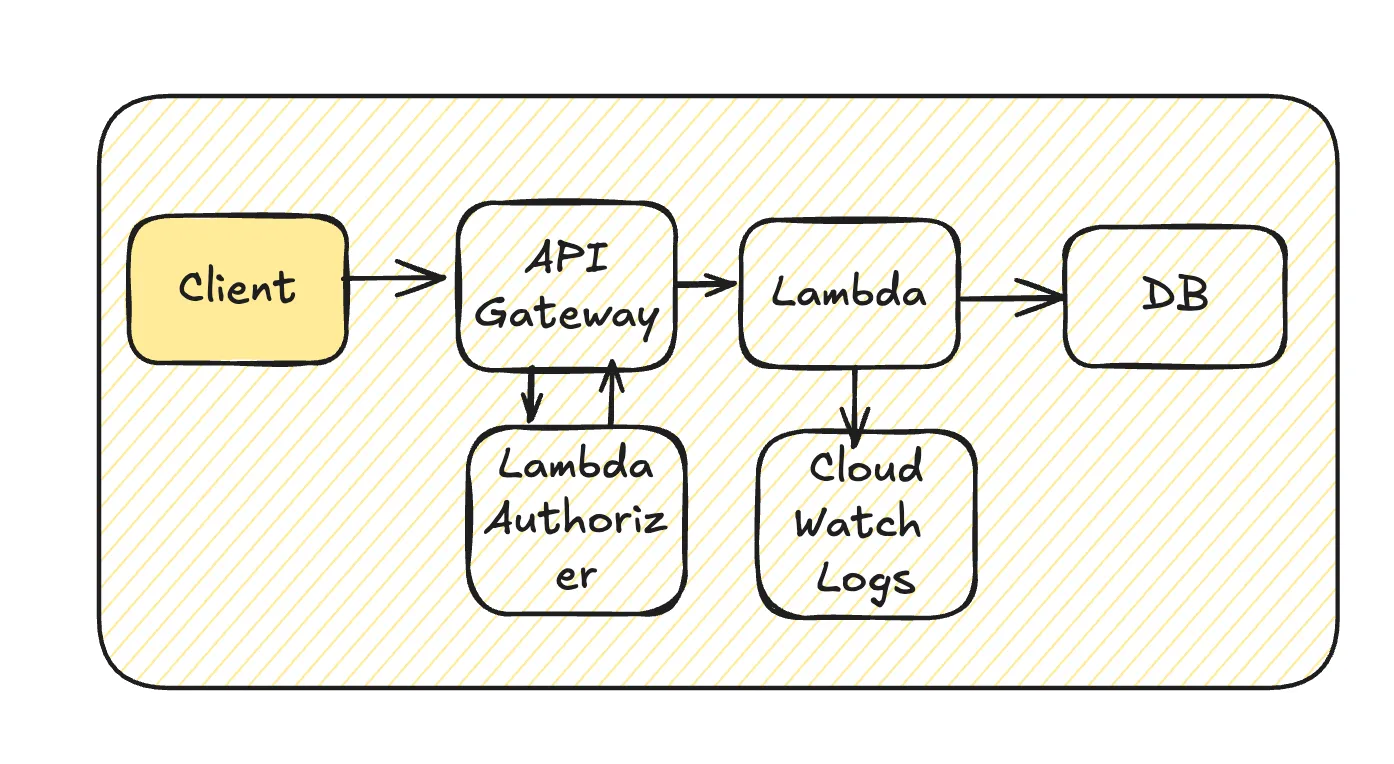
上記は基本的な図であり、Lambdaの内部では別のチームのAPIを追加で呼び出し、DBでのデータ追加変更はデータ基盤に流れ、ログはログ基盤に保存されるといった連鎖が続くことになります。
API Gateway + Lambdaとしていますが、ELB+ECSなどでもおおよそ同じです。
クライアントで抑える
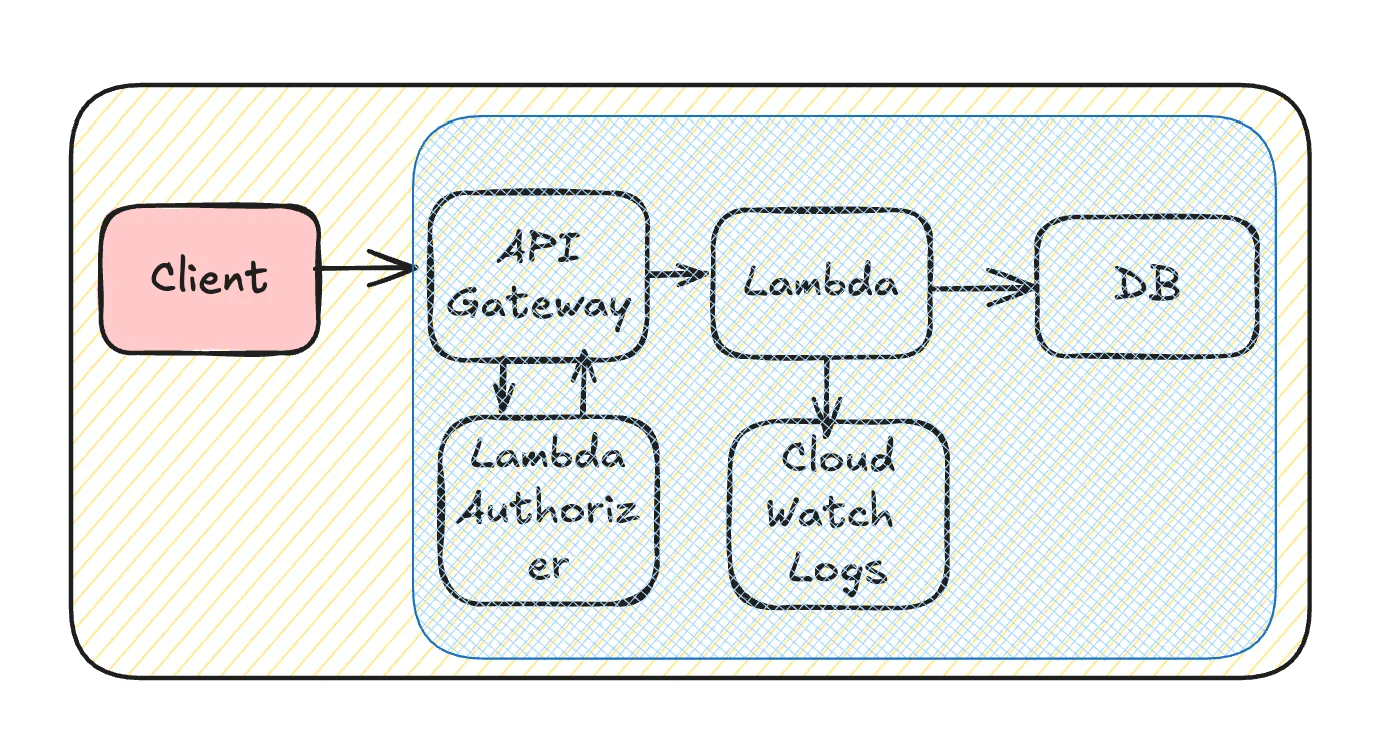
クライアントとバックエンドでの担当チームが異なるとやや難しいですが、起点だけあり一番効果が大きいです。
- ポーリングを控える。頻度を下げる
- 不要なリクエストを排除する
- クライアント側でキャッシュしてもらう
- リトライを抑える(ためにエラーリクエストを減らすことも可能。一部はバックエンドで対応可能)
特に基幹系アプリケーションでポーリングさせるとユニットあたり原価が跳ね、粗利率に対して大きい影響がありえます
API Gateway周辺で抑える
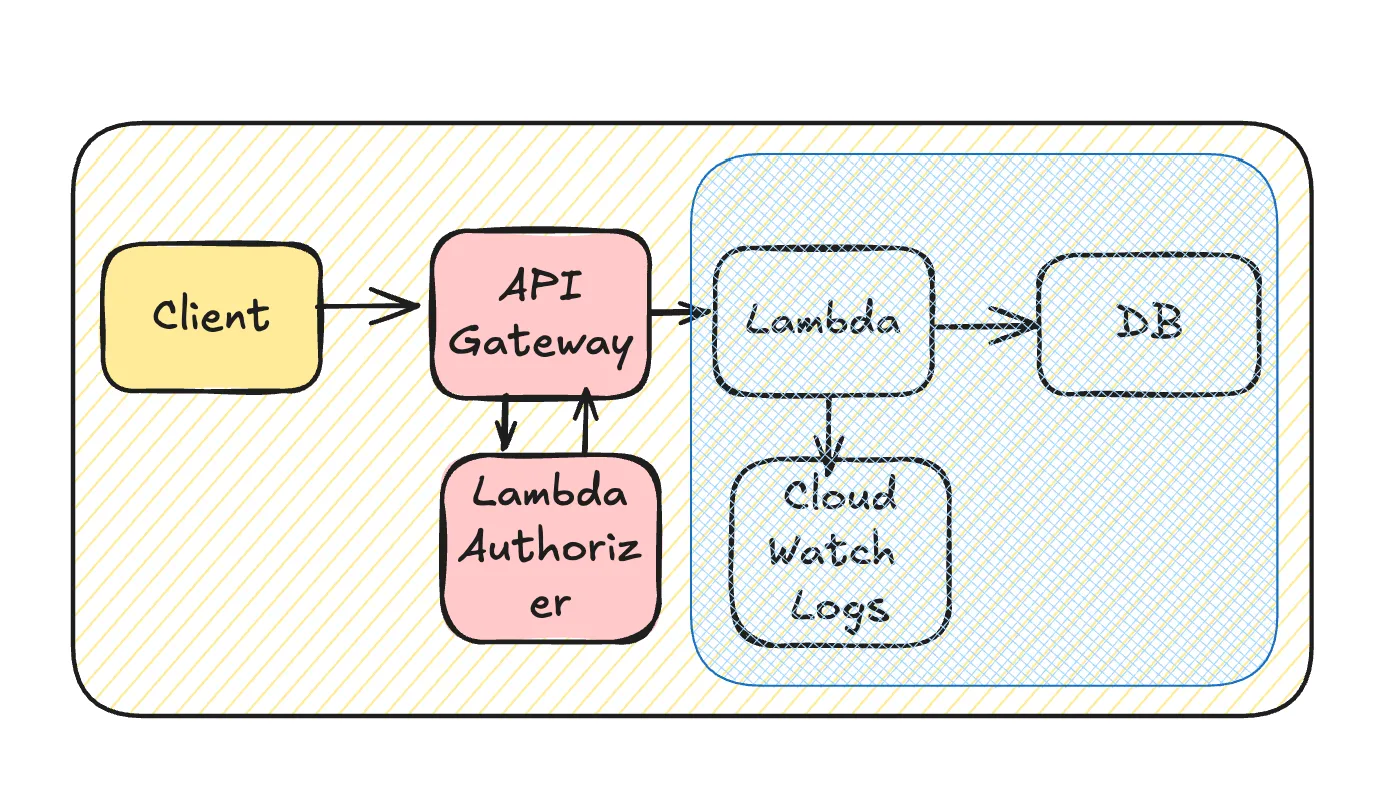
ELBでもだいたい同じです
- preflightリクエストのOptionsメソッドを固定レスポンスにする
- preflightリクエストにAccess-Control-Max-Ageをつける
- API Gatewayのキャッシュ機構を使う
- Lambda Authorizerのttlキャッシュを使う
- 処理不要でレスポンスの中身を問わないなら固定レスポンス機能を使う
- Lambdaを挟まず直接AWSサービスを呼び出すことも検討する
- マッピングテンプレート(VTL)だけで処理が終わらないか検討する
Lambdaで抑える
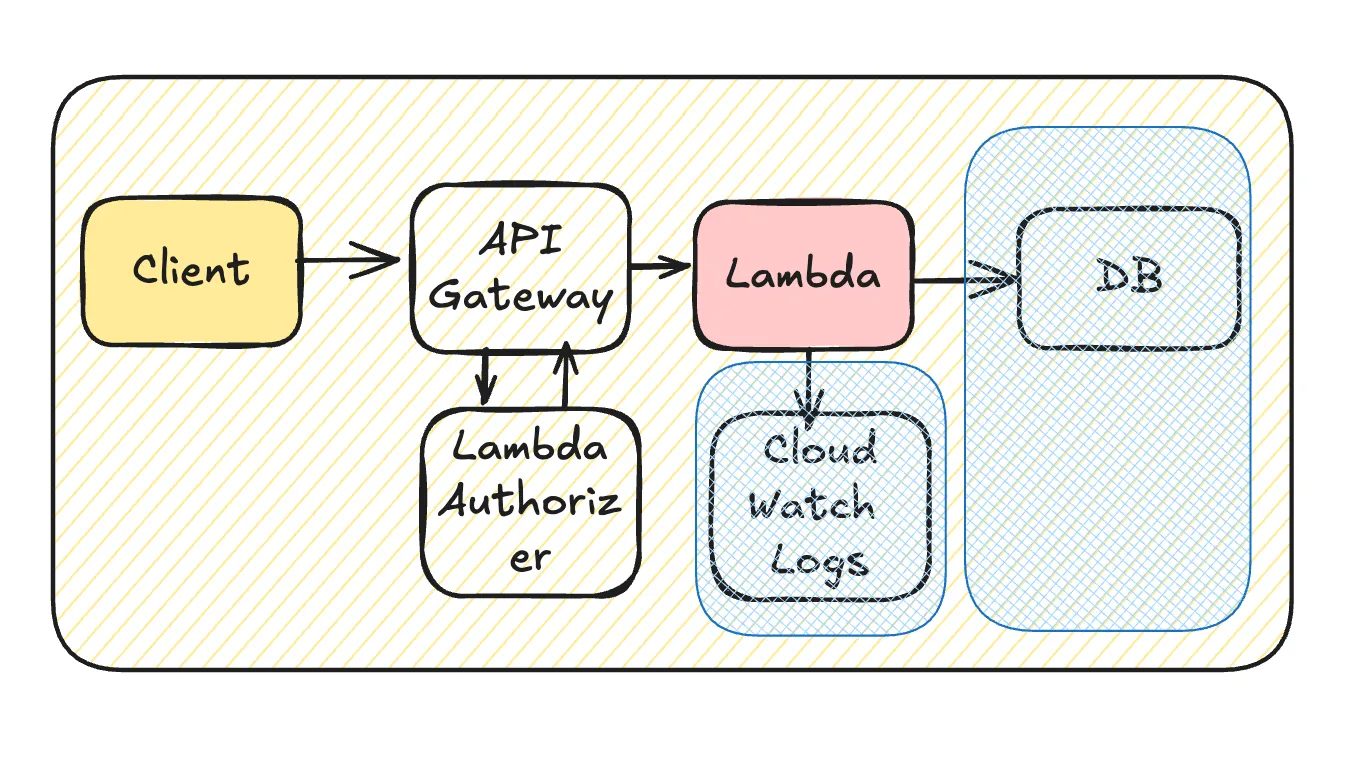
DBアクセスを控える、クエリチューニングするのは当然として、
ローカルメモリキャッシュを使う方法があります。ただしインスタンスレベルなので別のインスタンスには効果がないほか、インスタンス終了時に消えてしまいます。
初期起動の段階で全キャッシュする方法もあります。起動時にDBから取得して保存する、sqlite/levelDBなどを内蔵しておくなど。キャッシュの宿命で同期の方法は必ず検討しましょう(stale cache)
当然多数のインスタンスがあればすべてのインスタンスで保持されるわけなので無駄があるといえばあります。DBから全取得の場合、thundering herdが起きやすいのでトラブル時のカスケード障害に注意が必要です。ほとんど存在しない項目の存在チェックを毎回しているならブルームフィルタも効果的です。
リモートキャッシュという形でキャッシュサーバを準備する話になると、アーキテクチャレベルで修正が必要になるため割愛します。
次はログの部分です。ロギングの実装方法次第ですが、JSONを自前で組み立てると無駄な処理時間を使うのでロガーに任せましょう。テンプレート機能が活用できます。
このときログを少しでも切り詰めるとログ代が抑えられます。スペースを限界まで削る、キー名に略語を使い、uuidは切り詰める(そもそもuuidの必要性を確認する)
本番アプリケーションでスタックトレースをそのまま出すのはやめましょう。開発やライブラリ制作者用であり、本番でのトラブルシューティングにはほぼ使えません。きちんとコード内でハンドリングして行動に結びつくメッセージを出力するとよいです。
ログと一口に言ってもいろいろあり、監査に使うような「アーカイブ」ならCloudWatch Logsに直接出力する必要はありません。(保存エラー時の処理を検討しつつ、) S3に直接保存するほうがコストが抑えられます。
最後に
CloudTrailやGuardDutyあたりは後段のため、これらだけが増えることはなく起因があるはずです。
構造と流れ、数字とその変化を理解すればアセスメントと提案までは容易です。コストを本気で削減したいならDeepDiveしましょう。
クラウドコスト半減&原価作り込みに関心がある方は歓迎します。
コスト削減したい人向け記事集