生成AIがコードを読む時代、私たちはどうコードを理解すべきか?:生きているアプリケーションと死んでいるソースコード
あるプロダクトやアプリケーションを解析するとき、当然ソースコードを読みます。しかし、ソースコードだけでそのプロダクトが理解できるのでしょうか? ソースコードだけを読んでも、なぜこのアプリがエラーを出すのか、わからなかったことはありませんか?
ソースコードを使うメリット
改めて書くまでもないですが念のため
すべてが記載されている
ソースコードに基づいてアプリケーションが動く以上当然です
ソースがドキュメントだ。バグも完全に記述されている。 ――まつもとゆきひろ
『オブジェクト指向スクリプト言語Ruby』(まつもとゆきひろ/石塚圭樹(著)、アスキー)p.563 https://gihyo.jp/dev/serial/01/agile/0004 より孫引き
解析手順が豊富
プログラミング言語が生まれたときから機械化や調査の対象であり、手法も豊富です。
e.g. HotSpotの分析
生成AIが活用しやすい
コードなので構文としては似ており、要約や評価は生成AIが得意としているところです
ソースコード(だけ)を使うデメリット
ある程度生成AIで解決できますが、まだまだ不十分です。
量が多すぎて当たりをつけづらい
ソースコードは本にも例えられる通り分量が多いです。構造化されていればまだしも、構造化されてないならなおさら当たりをつけづらいですね。
抽象化を進め量を圧縮したならば、見たい部分を見るまでなんどもジャンプを求められることはよくあります。結局どこで設定しているのかわからない状態。
ある程度の規模を超えると生成AIでもコンテキスト量制限にかかります。
挙動が読みづらい
典型的な例として、依存関係の上書きがあります。Aという設定を複数の箇所で設定しているときの順位はコード見てもわからないでしょう。
さらに環境変数がソースコードの外で設定されていたらどうでしょう。
何をしたいのかが不明瞭
このソースコードによって最終的に何を解決するのかは不明瞭です。
結局readmeやドキュメント、誰かの解説頼りになります。
Howは豊富ですがWhy / So what?が不明瞭ということです。
コードだけ見てもコードの構造はわかりますがシステムの全体像を把握しづらいですね。
優先順位がつけづらい
よく使われるhotspotは確率であり、必ずしも重要とは限りません。普段触ってないファイルが重要かもしれません
作成したコード外の動きは教えてくれない
利用しているライブラリの動き、動作するOSの動きは教えてくれません。親切なときや不具合を修正したときは記録が残っていることがあります。
コードが使われているとは限らない
パスはあるが現実的には誰も呼んでないことも
見るべきは動いているアプリケーション
上記を解決…というより補完できるのが動的な解析です。
どのパスが重要かはAPIの呼び出し量から確認できます。どんな流れで動作しているかはAPMでわかります。パフォーマンスの問題検知も動かしたほうが速いです。コード見るよりログ見たほうが早いことも。
異常系として停止したときの動きが知りたいならカオスエンジニアリングが便利でしょう。正常系と異常系、両方通じることがそのシステムの専門家への近道です。
設計図だけ見てもよくわかりませんし、標本やDNAだけ見ても難しい。 (そこからだけで引き出すにはかなりの知識と観察力が必要です。)
実際の機械や生き物が動いているところを見れば一気に理解が進みます。旭川動物園のような行動展示です。
百聞は一見にしかずですね。体験しましょう
動的な解析と侵襲度
非侵襲的、つまり悪い影響を与えないほうが安全ではあります
メトリクス、トレーシング、ログの順に情報量と同時にリスク(侵襲度)が増えていきます。
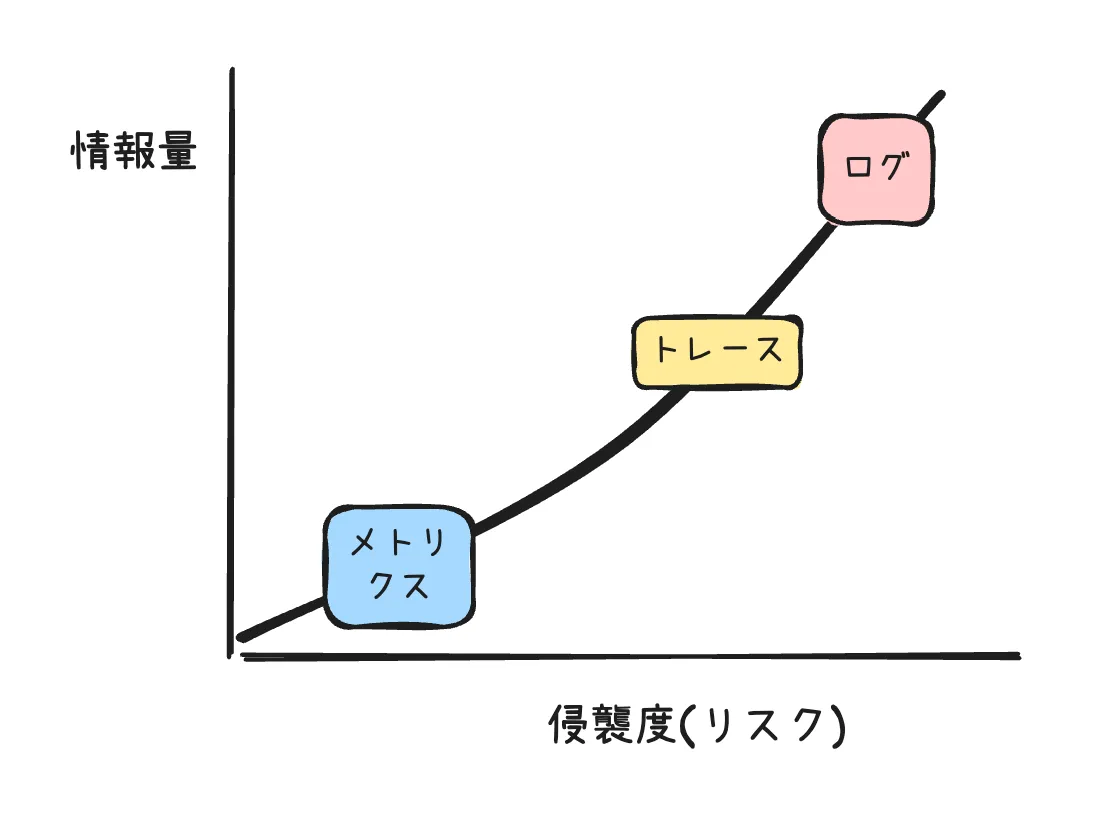
特にログは慎重に扱う必要があります。
ログのリスクはとにかく情報量が多いこととのトレードオフです。ディスクがいっぱいになる、ネットワークがログデータで埋まる、コストが嵩む、各種I/Oを消費する、ローテーション時に重くなる、アプリケーションのリトライなどで一気にログが増加する、ログ収集のリトライで一気に消費が増えるといった事象が起こり得ます。ログが原因でアプリケーションが停止するということです。逆にメトリクスだとそうそう起きません。
ソースコードと動的な解析、どちらが先か
生成AIでコードを要約しつつ、動的な解析をおすすめします。
動的にやってみて、その部分のソースコードを読むのを繰り返す。ある程度慣れてきたら通しで読む。
というのも、詳しくないものの理解を深めるにはまずメンタルモデルを組み立てる必要があるからです。
とりあえずやってみる:メンタルモデルの組み立て
学習のモデルはいろいろありますが、実務向けのEAT(Experience(経験)、Awareness(気づき)、Theory(理論))にせよ、Accelerated形式にせよ、まずはある程度行動してみることです。
メンタルモデルを組み立てたあとはモデルを修正していきます。固着したメンタルモデル自体が学習の障害になり得るので、柔軟に壊す。

理解を進めるうえでの改善
目的を持つことで理解が深めやすくなります。
ソースコードも漫然と読まず、疑問を持ちながら読んだり、改善点を見つけながら読みましょう。ソースコードの改善はもちろん、ドキュメントの改善、テストの追加…
バリデーションなどは簡単なシミュレータを作ることで便利になります。
動的な理解もそうです。どこが遅いのか、重要なAPIはどれか、リスクが大きそうな部分はどこか…自問自答しましょう。
最後に
生成AIでだいぶ楽になったところはあっても、新規プロジェクトを除けば開発のうちほとんどがコード理解と言われますし、実際にそう感じます。
長い時間アプリに関わっていても理解が浅い人はだいたいObservabilityに興味がありません。理解が早くて深い人になるために、実際に動いているアプリケーションを見て触り観測しましょう。