Python Defaults That Hurt Performance
Python is often described as slow.
In practice, however, much of that perception comes not from the language itself, but from relying on its defaults.
Python prioritizes readability and backward compatibility. As a result, its default settings are not always optimized for performance.
In this article, we’ll look at a few common “default traps” that are easy to overlook in production systems.
Running an outdated Python version
Python versions have a direct impact on performance.
Starting from Python 3.11, the Faster CPython project has introduced significant interpreter-level optimizations with each release.
Despite this, older versions are still widely used due to compatibility concerns, operational constraints, or simply because tutorials and onboarding materials lag behind.
This is one of the simplest—and most impactful—performance traps.
New versions are typically released around October each year, so it’s worth keeping track.
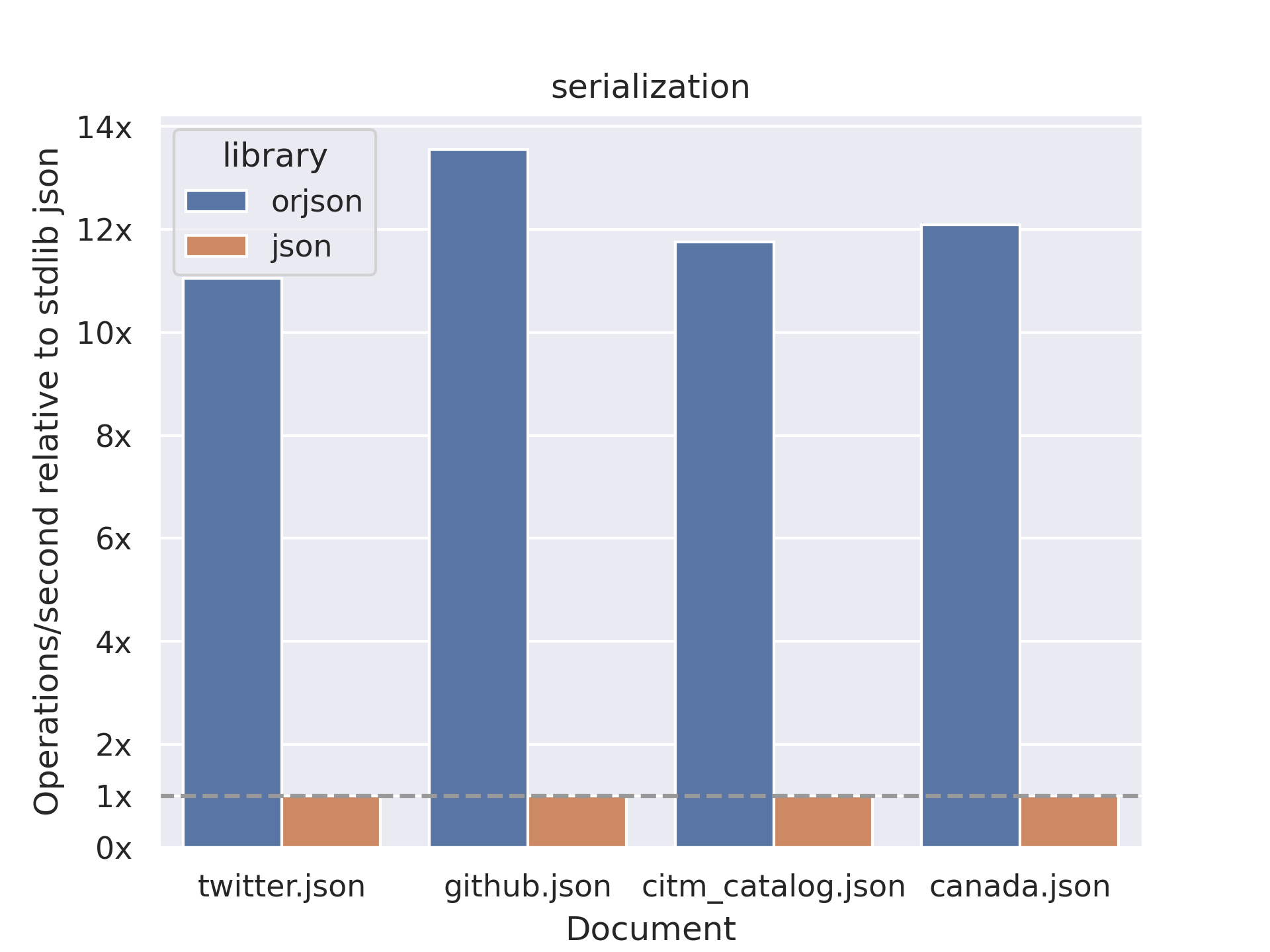
Using the standard json library by default
Python’s standard library is reliable, but not always fast.
In many other languages, high-performance JSON handling is closer to the default experience. In Python, this is not necessarily the case.
Given how central JSON is—across APIs and data processing alike—the standard json module can become a bottleneck, especially in CPU-bound workloads.
Libraries such as orjson or simdjson are often worth considering.
Recreating HTTP/TCP connections (e.g., boto3)
Connection reuse and pooling are widely supported across modern languages and libraries.
However, how much benefit you get “by default” depends heavily on API design and usage patterns.
In Python, it is easy to write simple code that unintentionally recreates connections on every request. Without explicit configuration, you may not benefit fully from keep-alive or connection pooling.
For example, libraries such as boto3 or requests require careful handling of connection reuse.
If left unaddressed, repeated connection setup can increase both latency and cost.
Converting iterables to lists too early
Python makes heavy use of iterators.
While lazy evaluation and streaming are widely emphasized across modern languages, it is still common in Python to eagerly convert everything into lists.
This pattern can lead to:
- unnecessary memory allocation
- repeated full scans of data
As data volume grows, this can become a significant performance issue.
Avoid designs that repeatedly convert iterables to lists, process everything, and then reconstruct iterables again. Pay attention to how many full passes your code performs.
Blocking I/O and synchronous execution
Python code is often concise, but it can hide significant I/O wait time.
If you simply write API calls in sequence, they will execute sequentially. In many cases, these operations are also blocking, meaning no other work is done while waiting for I/O.
Modern languages often provide stronger default support for asynchronous execution.
In Python, however, concurrency typically needs to be introduced explicitly.
When your workload is dominated by I/O latency, using async or parallelism can significantly improve throughput.
Tooling also matters (uv, ruff)
Python’s tooling ecosystem has long been fragmented, but fast, modern tools such as uv and ruff have gained rapid adoption.
These tools are designed to be fast even with minimal configuration, and can noticeably improve the developer experience compared to traditional toolchains.
For new projects, they are worth considering.