Breaking the Cost Chain: A Deep Dive into Reducing AWS Costs via Service Dependency Optimization
💰 Struggling to optimize AWS costs despite tweaking individual services?
Many engineers fine-tune AWS resources — adjusting Lambda memory settings, optimizing EC2 instance types, or enabling S3 lifecycle policies — expecting noticeable cost savings. But despite these AWS cost optimization efforts, total AWS expenses often remain stubbornly high.
The real issue? Hidden cost chains. A single S3 request can trigger CloudTrail logging, which then feeds into GuardDuty analysis, creating a cascading effect that inflates your AWS bill.
This guide provides actionable AWS cost optimization strategies for DevOps engineers, SREs, and FinOps professionals looking to reduce AWS costs at scale by breaking down interdependent cost chains. We’ll explore high-impact optimizations that go beyond isolated fixes, helping you minimize AWS expenses without sacrificing performance or security.
🚀 Let’s dive into AWS cost chain optimization best practices and start cutting unnecessary cloud expenses today.
AWS Config -> SecurityHub -> GuardDuty
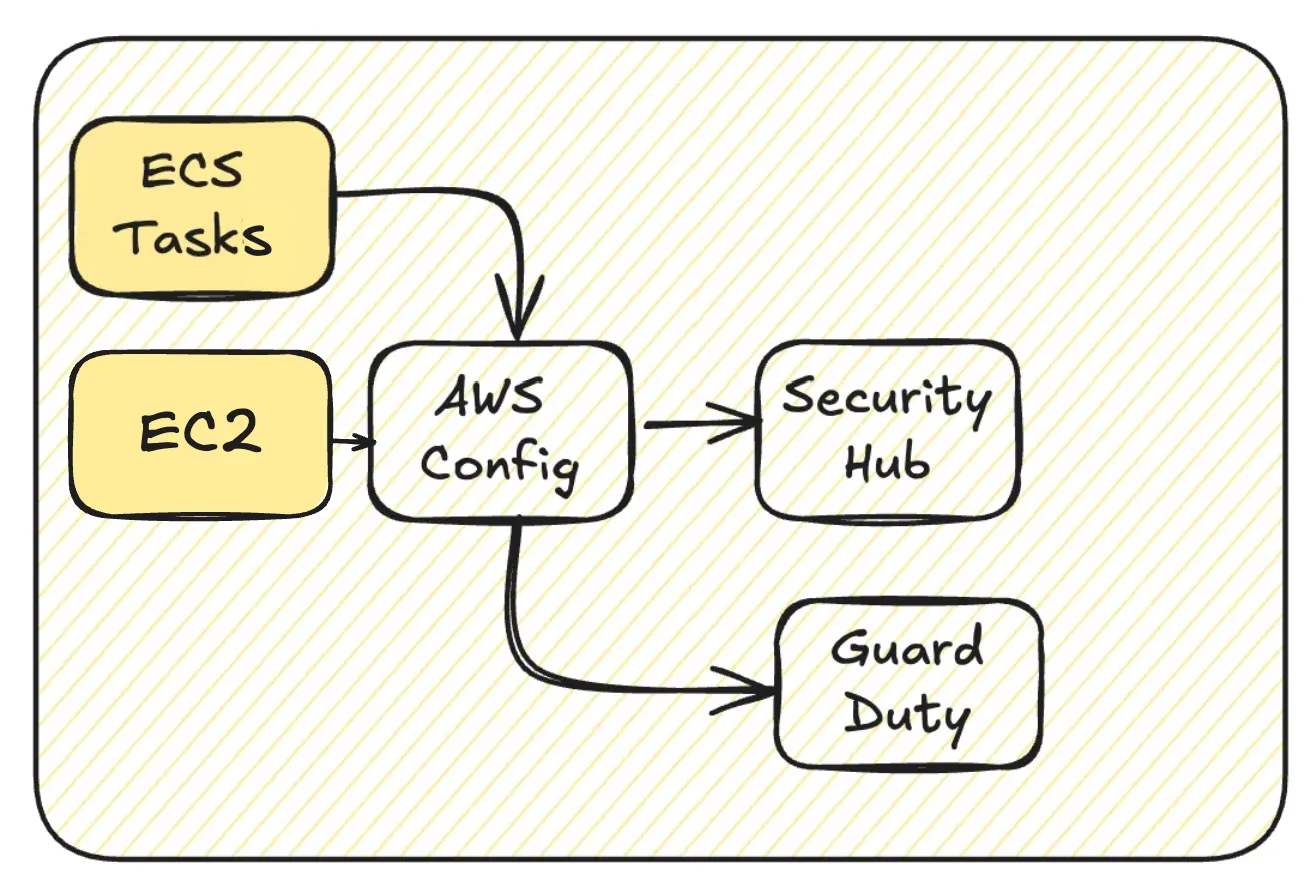
Frequent start/stop cycles of ECS tasks or EC2 instances generate network interface events. These events are recorded by AWS Config and subsequently analyzed by Security Hub, forming another cost chain that adds to your overall expenses.
When running off-the-shelf solutions like Databricks on AWS, frequent EC2 instance lifecycle events are common, further increasing the volume of logged network interface changes.
In some cases, Amazon Inspector may also contribute to this cost chain, depending on your security configurations.
💰 Quick Wins
or
Optimizing from the First Trigger: ECS Task Launches
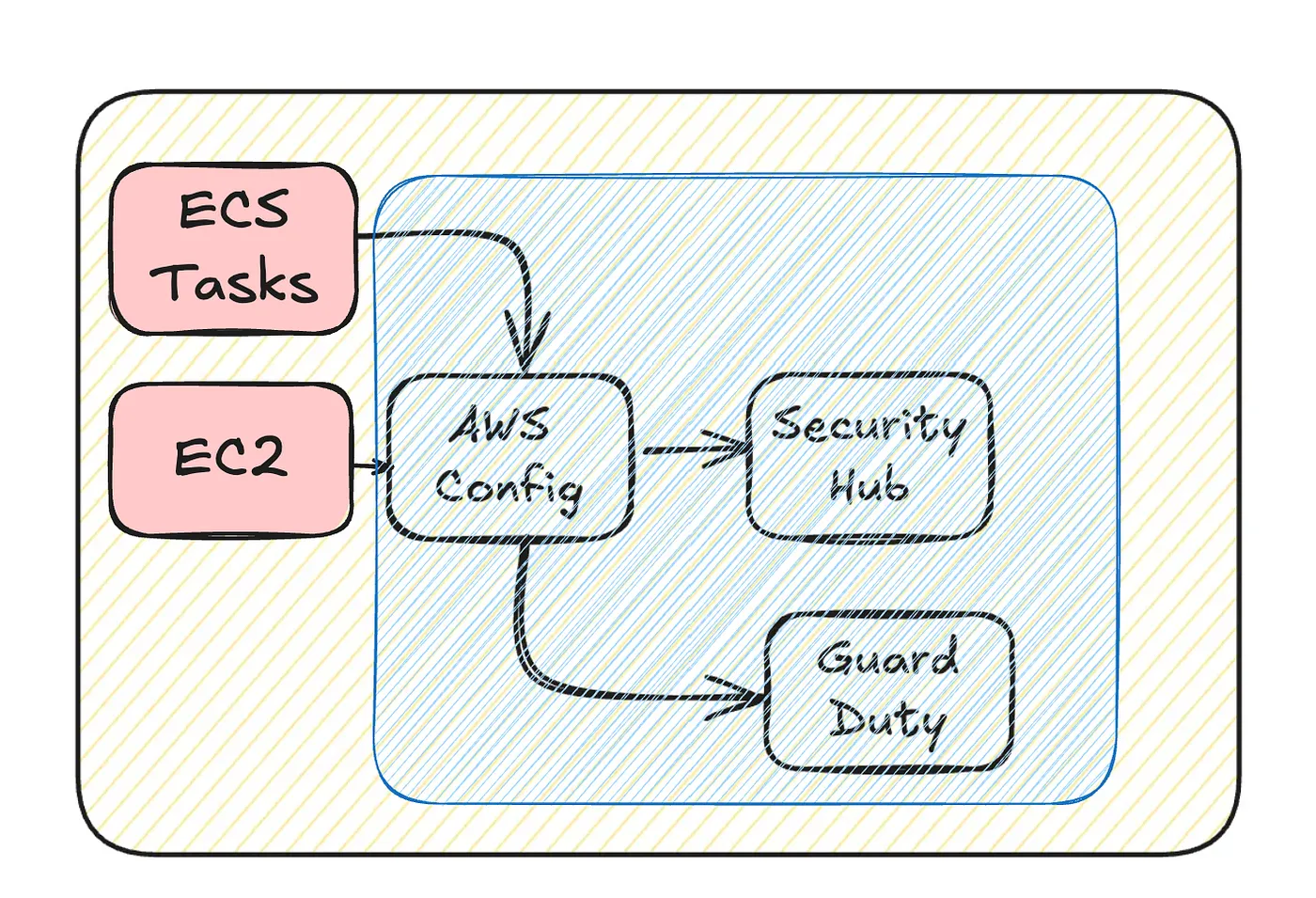
Reducing the number or frequency of ECS Task launches can help lower costs. However, achieving this often requires architectural changes, which can be complex and challenging to implement.
Minimizing AWS Config Logs
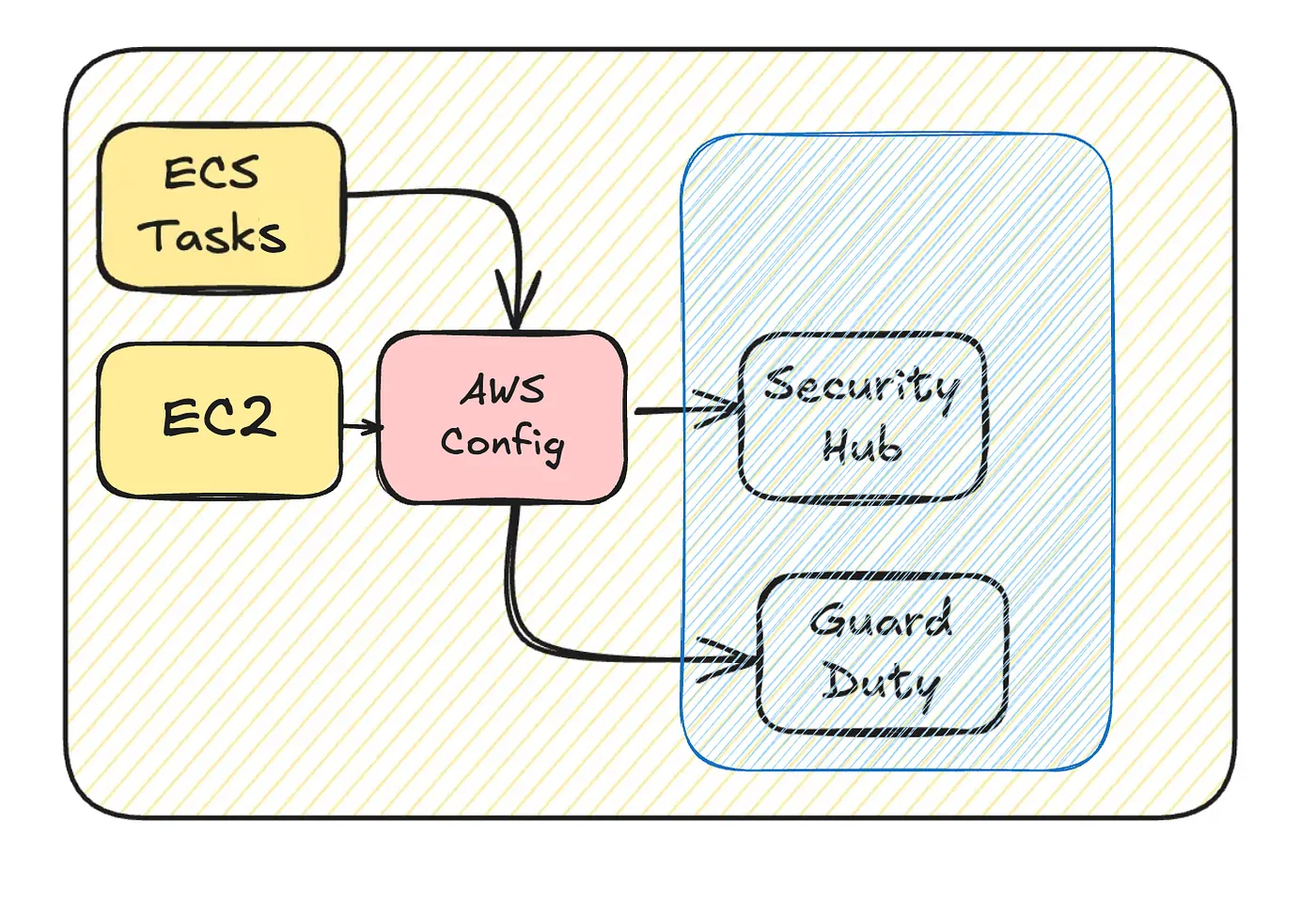
The key optimization here is reducing AWS Config logging overhead. There are two main approaches:
Choose the best approach based on your workload, existing security measures, and security requirements to ensure an optimal balance between cost savings and compliance.
S3 -> CloudTrail -> GuardDuty
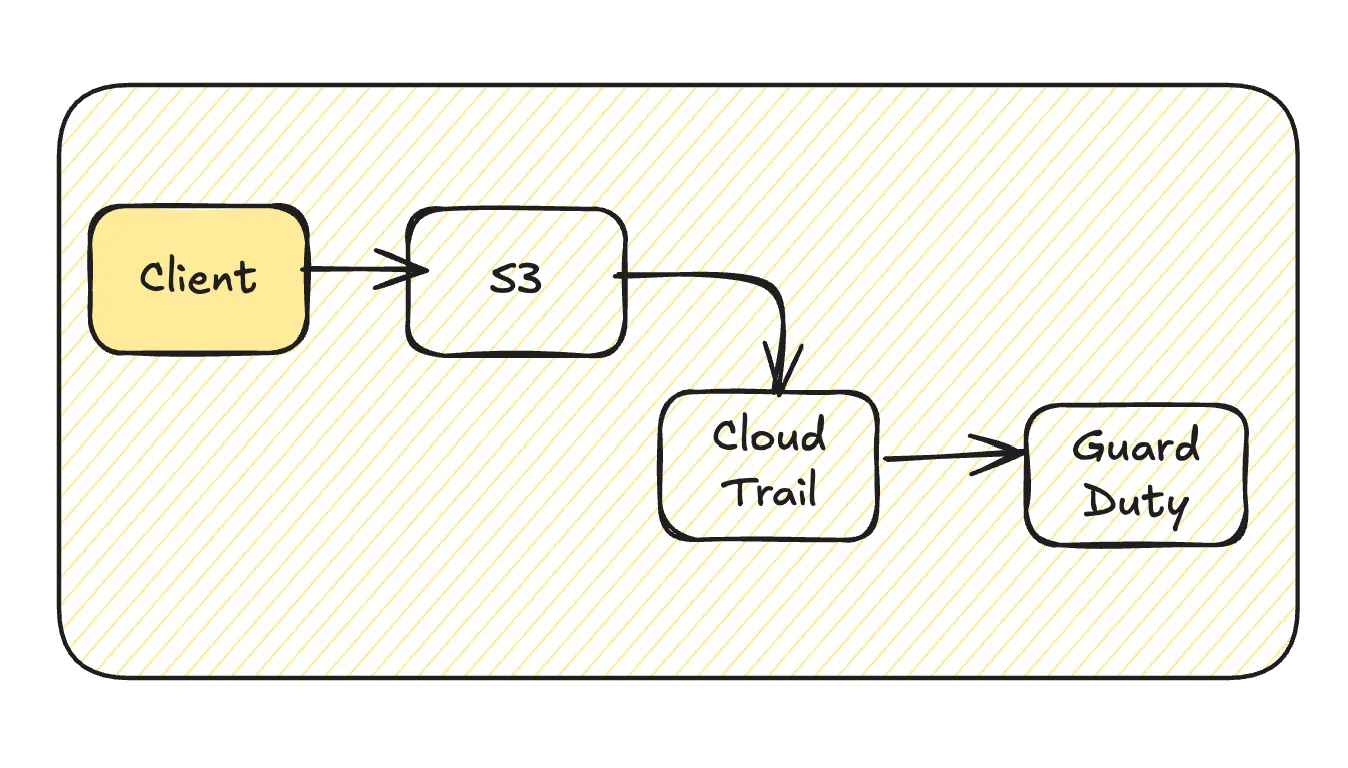
Requests to S3 objects are logged as data events in CloudTrail. These events are then audited by GuardDuty, creating a cost chain that compounds expenses across services.
Optimizing from the First Trigger: S3 Access
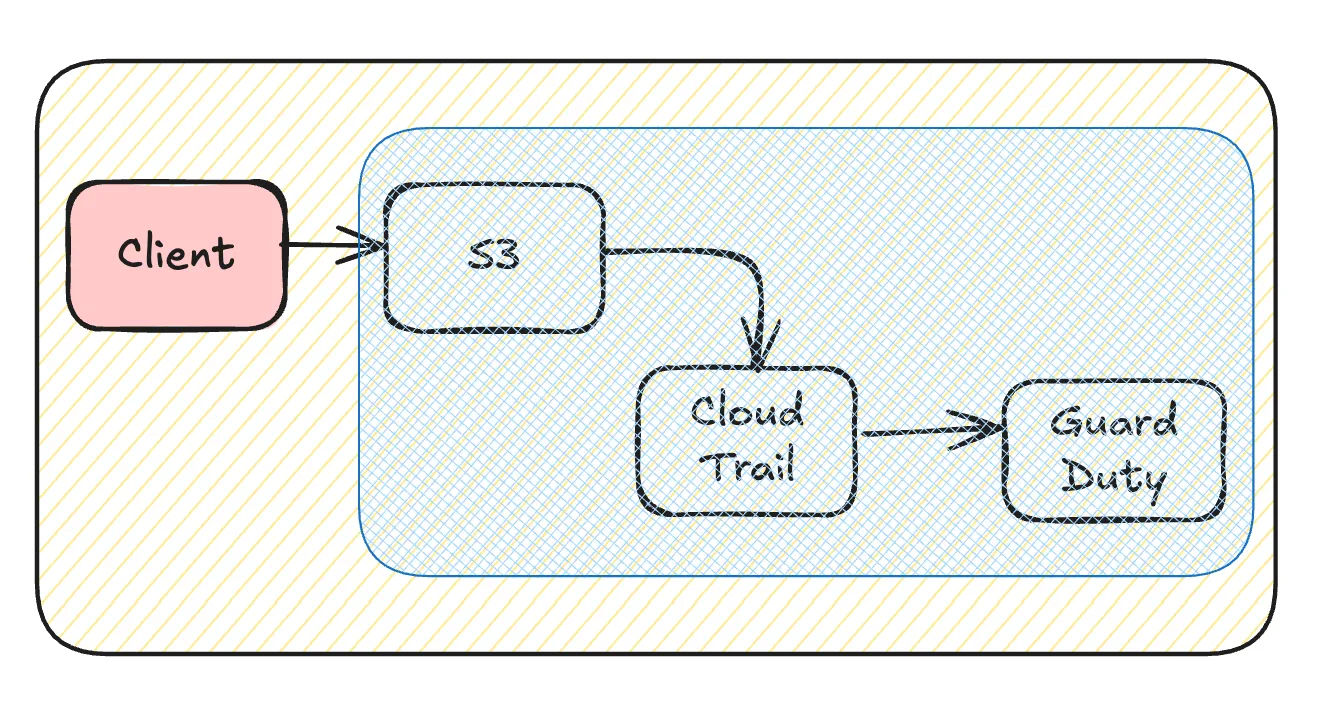
- Implement CloudFront if external access is high. Unlike direct S3 requests, CloudFront requests are not logged in CloudTrail, but access logs can still be obtained.
- Use signed URLs to minimize direct API calls to S3.
- ConsiderS3 Inventoryfor frequent object listings as a cost-effective alternative.
- Review table formats and access patterns in data pipelines to optimize performance.
In addition, executing a large number of Athena queries can generate a high volume of “StartQuery” events in CloudTrail.
Reducing CloudTrail Logging Overhead
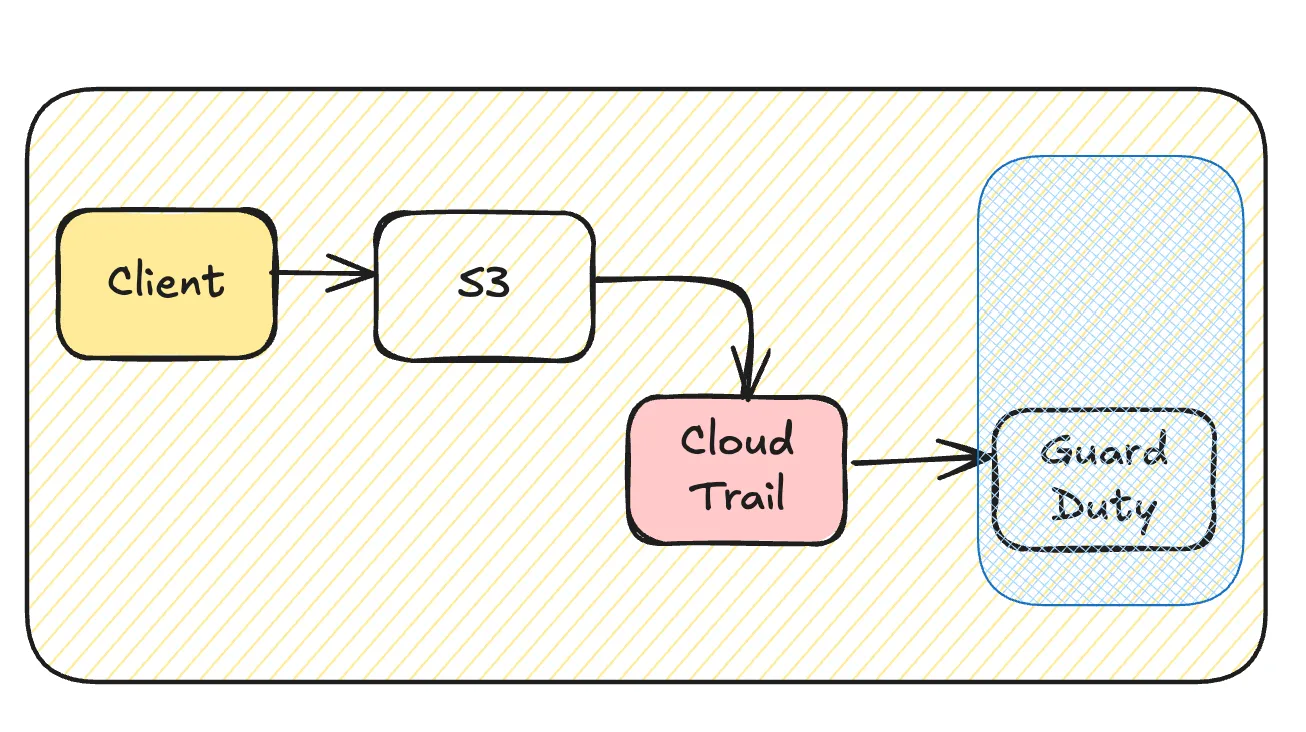
CloudTrail allows you to filter data events, reducing unnecessary logging overhead. Evaluate the impact of excluding specific logs based on your workload, existing security measures, and compliance requirements.
However, be cautious — removing logs may affect traceability and limit forensic capabilities.
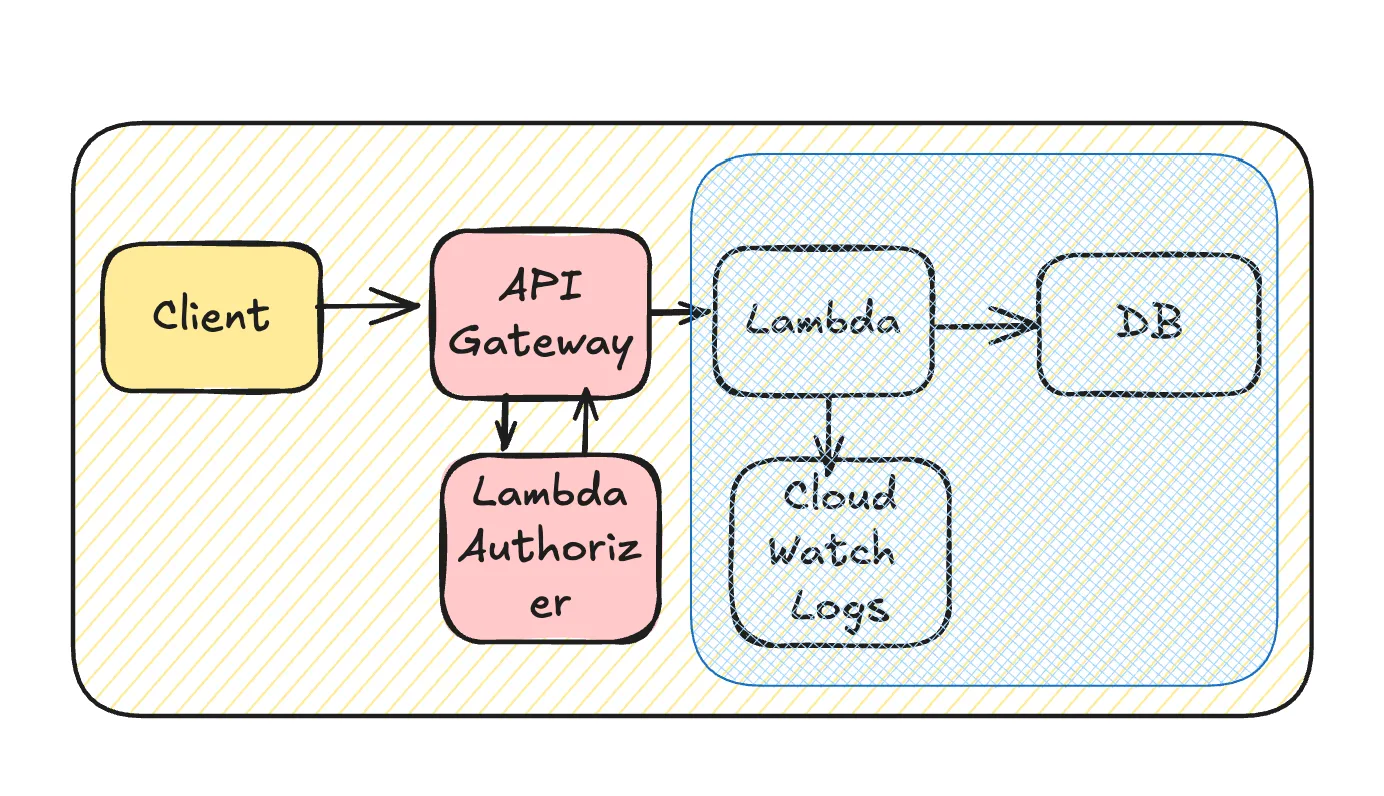
API Gateway + Lambda
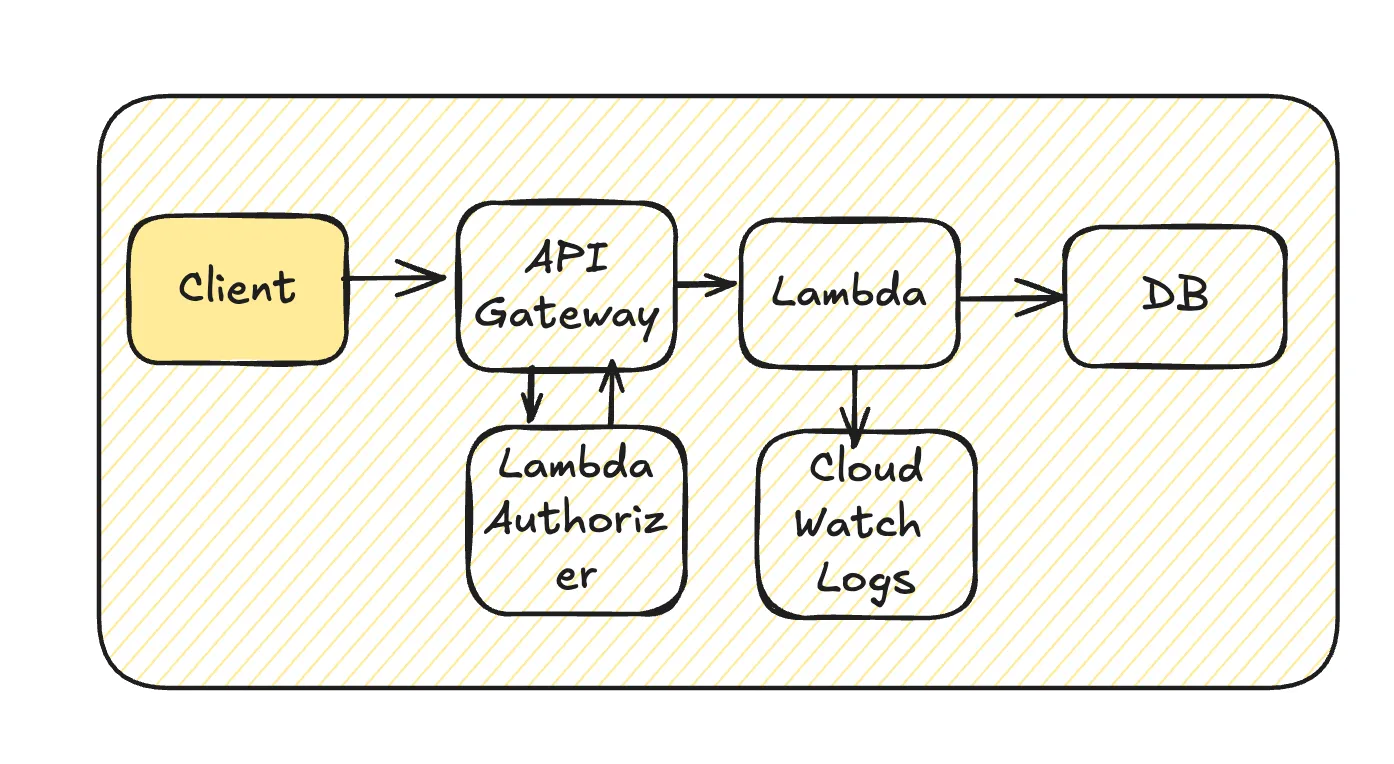
The diagram above represents a basic architecture. However, within the Lambda function, additional API calls to other teams’ services may occur, database updates propagate to the data platform, and logs are stored in the logging infrastructure — forming an extended chain of dependencies.
Although this example uses API Gateway + Lambda, a similar architecture can be implemented with ELB + ECS with comparable results.
💰 Quick Wins
- Optimize preflight requests: Use a fixed response for OPTIONS method requests.
- Set Access-Control-Max-Age for preflight requests: Reduce the frequency of repeated CORS preflight requests.
- Use fixed responses when processing is unnecessary: If the response content does not matter, use API Gateway’s fixed response feature.
Optimizing at the Client Side
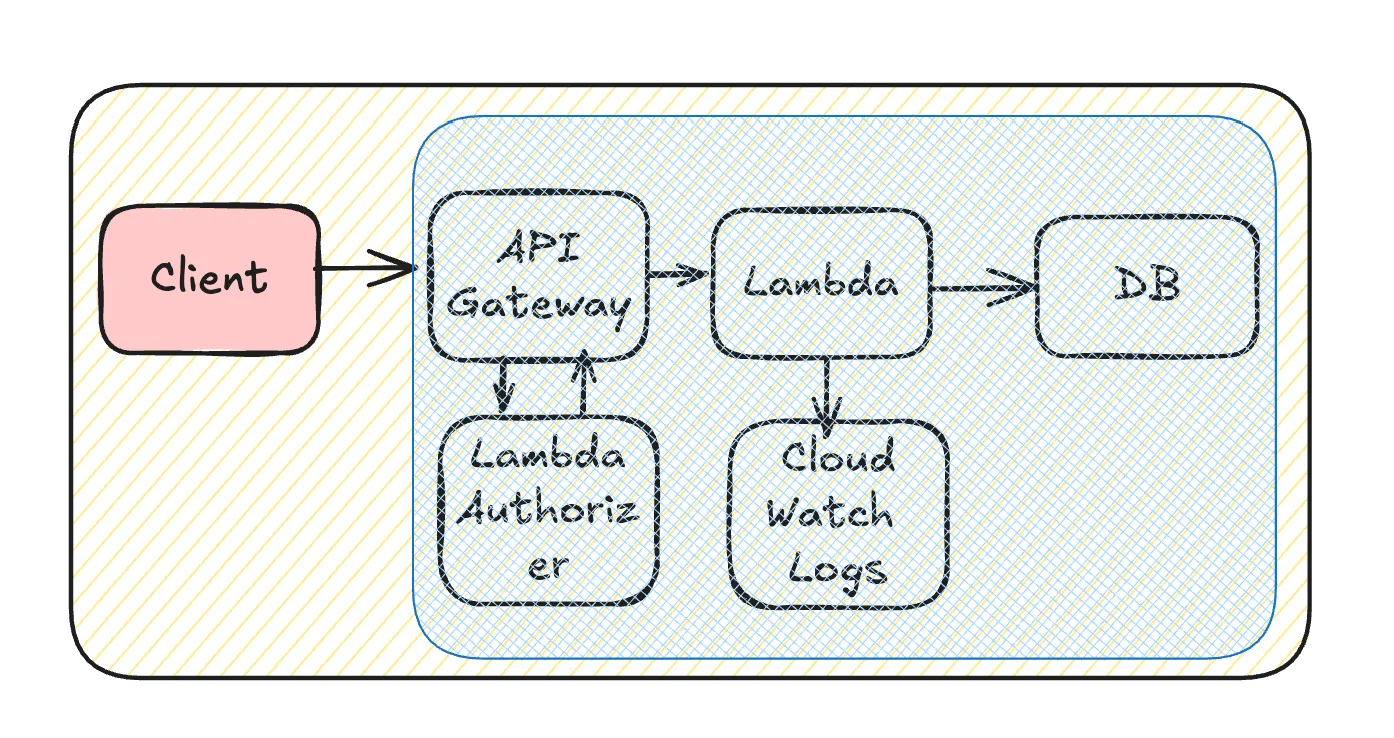
Reducing unnecessary requests at the client side is one of the most impactful optimizations since it directly reduces the load on the backend. While this can be challenging when different teams manage the client and backend separately, addressing inefficiencies at the source yields the greatest cost savings.
Key Strategies:
- Minimize polling: Reduce the frequency of polling or avoid it whenever possible.
- Eliminate unnecessary requests: Prevent redundant API calls that do not add value.
- Leverage client-side caching: Encourage caching to minimize duplicate requests.
- Reduce retries: Decrease error-prone requests to limit automatic retries (some cases can be handled on the backend).
In enterprise applications, excessive polling can significantly increase per-unit costs, potentially impacting gross margins.
Optimizing Around API Gateway
The same optimizations generally apply to ELB as well. Reducing overhead at the API Gateway level can improve performance and lower costs.
Key Strategies:
- Optimize preflight requests: Use a fixed response for OPTIONS method requests.
- Set Access-Control-Max-Age for preflight requests: Reduce the frequency of repeated CORS preflight requests.
- Leverage API Gateway caching: Store frequent responses to minimize redundant processing.
- Enable TTL caching for Lambda Authorizer: Reduce the number of authorization calls.
- Use fixed responses when processing is unnecessary: If the response content does not matter, use API Gateway’s fixed response feature.
- Consider calling AWS services directly instead of using Lambda: Reduce unnecessary function invocations.
- Evaluate whether processing can be handled with mapping templates (VTL) alone: Avoid Lambda where possible by utilizing API Gateway’s built-in processing capabilities.
Minimizing Overhead in Lambda
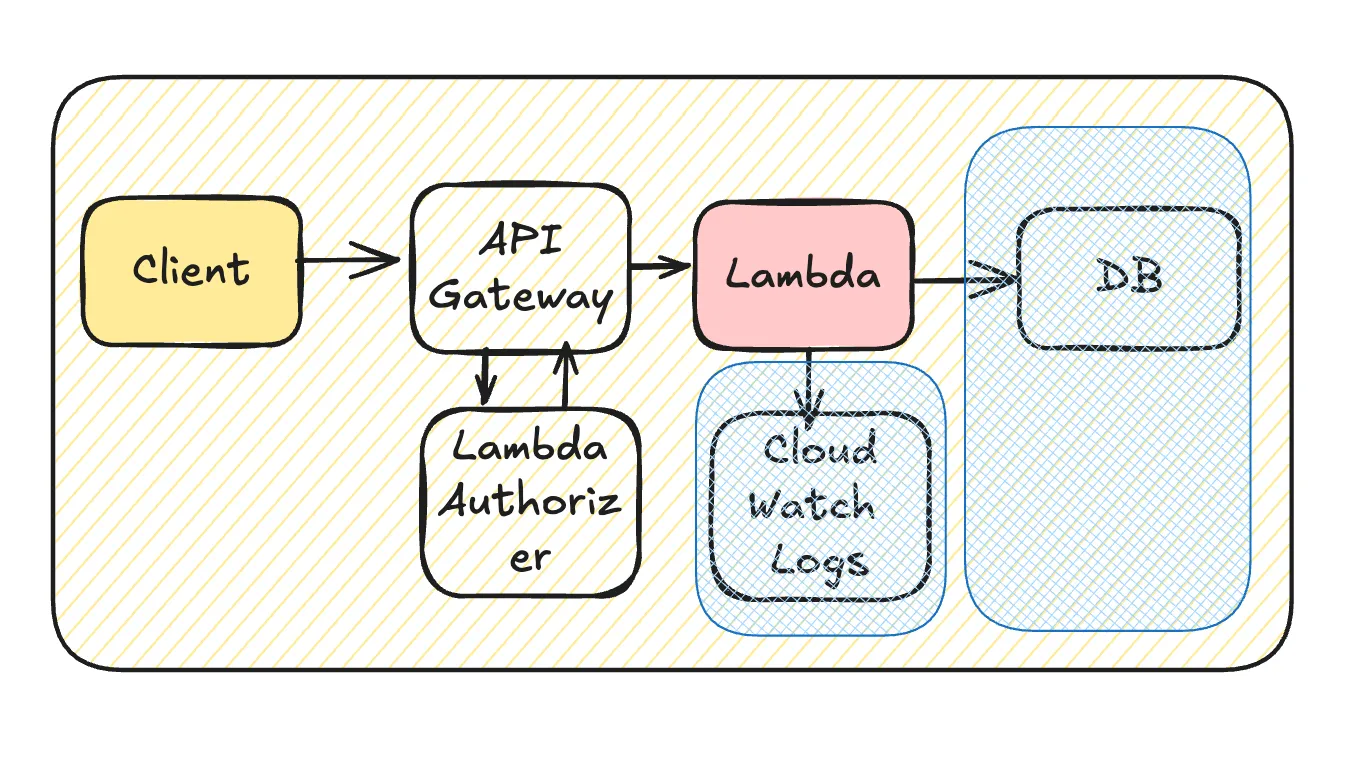
Optimizing Database Access and Caching
While optimizing queries and minimizing database access is fundamental, additional caching strategies can further reduce overhead.
- Leverage local memory caching: This can improve performance, but it is instance-specific, meaning it does not persist across instances and is lost when the instance is terminated.
- Preload data at startup: Fetch necessary data from the database at startup and store it locally, or embed a lightweight database like SQLite or LevelDB. However, caching inherently introduces stale cache risks, so synchronization strategies must be carefully considered.
- Be mindful of redundancy: If multiple instances maintain separate caches, memory usage may become inefficient. Additionally, bulk retrieval from the database at startup can trigger a thundering herd problem, potentially leading to cascading failures.
- Use Bloom filters for rare existence checks: If your system frequently checks for the existence of rarely used items, Bloom filters can be an effective solution.
- Remote caching requires architectural changes: Using a dedicated cache server (e.g. Redis) involves architectural modifications and is beyond the scope of this discussion.
Optimizing Logging for Cost Efficiency
The way logging is implemented significantly impacts performance and cost.
- Avoid unnecessary processing when structuring logs: Instead of manually constructing JSON logs, rely on logging libraries with built-in template functions to minimize overhead.
- Reduce log size to lower costs: Optimize storage by eliminating unnecessary spaces, using abbreviations for key names, and truncating UUIDs (after verifying if full UUIDs are truly necessary).
- Do not expose full stack traces in production: Stack traces are primarily useful for development and library maintainers but are rarely effective for production troubleshooting. Instead, ensure proper error handling and output actionable log messages that guide resolution steps.
- Optimize long-term audit logs: If logs are intended for long-term retention and auditing, storing them directly in S3 instead of CloudWatch Logs can significantly cut costs. However, ensure proper handling for storage failures.
Final Thoughts
CloudTrail and GuardDuty operate downstream in the service chain, meaning their cost increases are always triggered by upstream events. Identifying the root cause is key to effective cost optimization.
By understanding the architecture, data flow, and numerical trends, conducting assessments and making recommendations becomes much easier. If you’re serious about cost reduction, it’s time to Deep Dive.
Recommended Articles for Cost Optimization
This article is the English version of the original article written in Japanese, available here.